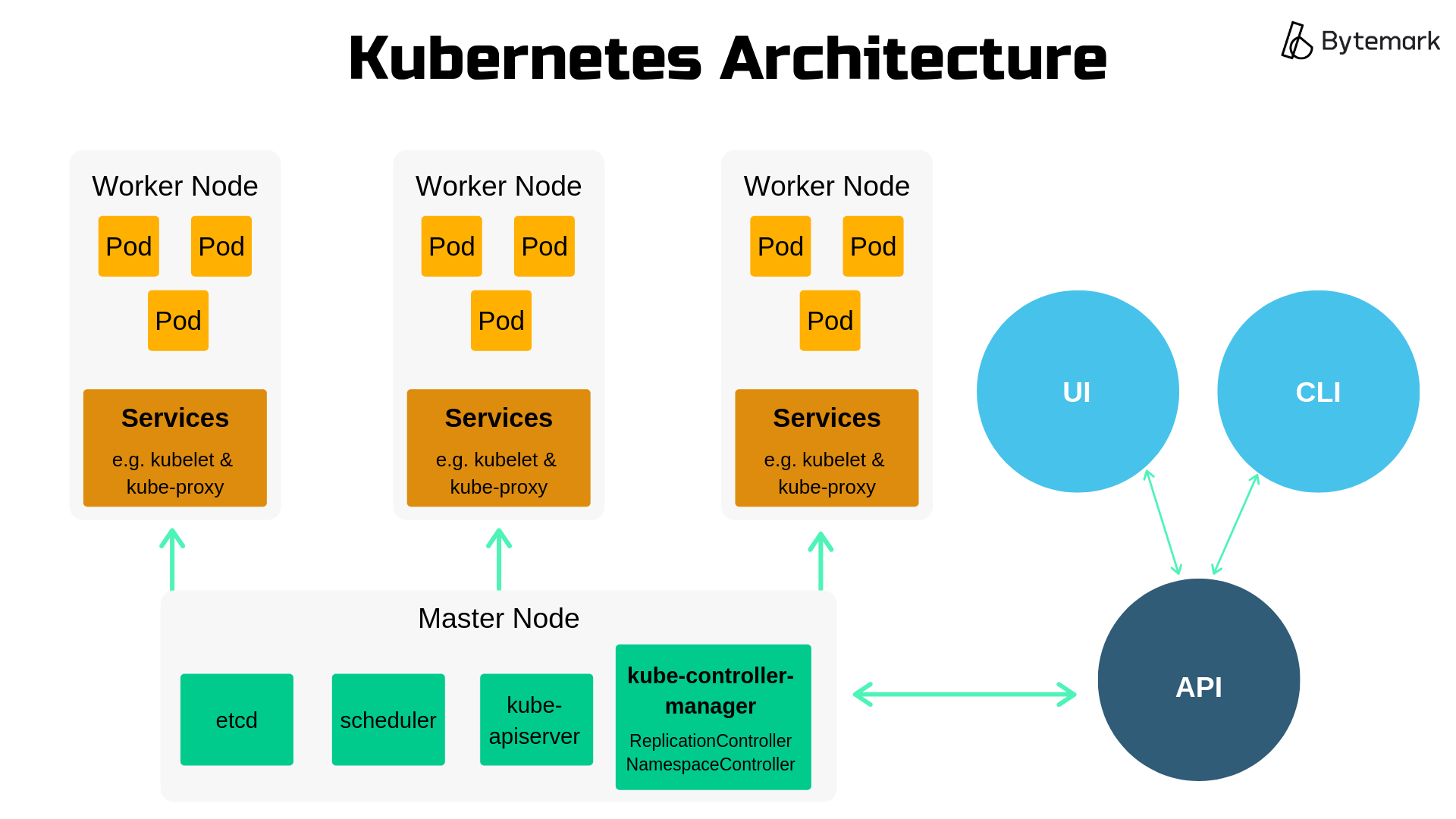
Kubernetes is an open-source container orchestration system that automates deployment, scaling, and management of containerized applications. To effectively use Kubernetes, it is important to understand some key concepts involved.
Minikube vs Full-Fledged Kubernetes Cluster
Minikube is a lightweight tool that allows developers to run a single-node Kubernetes cluster locally for testing and development purposes. It provides an easy way to learn and experiment with Kubernetes without the complexity of a full production cluster. In contrast, a full-fledged Kubernetes cluster is typically used for production workloads across multiple physical or virtual machines to provide high availability and scalability for business-critical applications. Key differences are that Minikube has limited resources and a simplified architecture compared to production-grade clusters with advanced features like high availability and distributed architectures.

Namespaces
Namespaces are used in Kubernetes to organize and isolate groups of name conflicting resources like pods, services, deployments etc. within a cluster. The default namespace is called “default” but additional namespaces can be created to logically separate containers by purpose, ownership or environment. Access controls can then be applied on a per-namespace basis using roles and role bindings. Namespaces are useful for multi-tenant clusters shared by different teams, projects or environments.
Pods and Containers
Pods are the basic building blocks of Kubernetes that represent a group of one or more containers sharing storage and networking resources, scheduled and managed together on a node. Containers within a pod share an IP address and port space so they can find each other. Pods allow containers to be treated and deployed as logical units for high availability rather than individual container instances. They enable co-located containers that are tightly coupled in an application stack.
Deployments and ReplicaSets
Deployments in Kubernetes are used to declare and manage the state of containerized applications and ensure that the desired number of replicas are available and healthy at all times. Deployments manage ReplicaSets that maintain the desired number of pod replicas specified. ReplicaSets ensure pods are recreated if they fail or are terminated. Updating a Deployment’s pod template causes rollout of new ReplicaSet pods without affecting existing pods. This allows automated rolling updates and rollbacks of applications in production.
Services and Load Balancing
Services in Kubernetes provide a single stable point of access for pods. They expose pods to the rest of the cluster internally using selectors to identify target pods. External services are exposed outside the cluster through Ingress resources. Services enable discovery and load balancing of pods which are ephemeral and can be rescheduled. Common service types include ClusterIP (internal), NodePort and LoadBalancer (external access). Services act as virtual IPs simplifying pod access within and outside the cluster.
Kubernetes Networking Model
The Kubernetes networking model uses several primary components to enable communication between pods across nodes. Each node has a unique ClusterIP that pods use for communication with services. Pod network plugins like Flannel and Calico are used to assign IPv4/IPv6 addresses and enable connectivity among pods. CNI (Container Network Interface) provides network integration for containers. Kubernetes also uses kube-proxy for simple services load balancing. By abstracting away networking details, Kubernetes enables advanced network topologies for cloud-native applications.
Persistent Volumes and Storage Classes
For persisting application data across pod recreation and rescheduling, Kubernetes uses Persistent Volumes (PVs). Storage administrators can provision required volume types like NFS, iSCSI, AWS EBS, and make them available as PV objects. PV claims are made by developers and bound to PVs. Developers can optionally specify storage classes to get dynamically provisioned volumes for varying performance and cost. This separates storage management from container provisioning supporting both integrated and 3rd party cloud storage systems.
Content input:
In this article, we will discuss the Kubernetes RBAC (Role-Based Access Control) system and how it can be used to authorize access to resources in a Kubernetes cluster based on roles and bindings.
What is Kubernetes RBAC?
Kubernetes RBAC is an authorization system that defines which users and groups can access which resources within a Kubernetes cluster. It uses roles and bindings to grant permissions to resources based on user identities like users, groups or system user accounts.
ClusterRoles vs Roles
In Kubernetes, there are two types of roles:
- ClusterRoles grant access permissions across all namespaces in the cluster. This includes access to cluster-scoped resources like nodes, persistent volumes, etc.
- Roles grant access permissions only within a single namespace.
Roles and ClusterRoles specify access permissions in the form of rules like what actions can be performed on which resources.
RoleBindings and ClusterRoleBindings
Roles and ClusterRoles are then bound to users and groups using RoleBindings and ClusterRoleBindings respectively.
- RoleBindings tie Roles to users and groups within a namespace.
- ClusterRoleBindings tie ClusterRoles to users and groups cluster-wide across all namespaces.
This binds the permissions defined in roles to the subjects (users, groups or service accounts) granting them the specified access.
Managing Authorization using RBAC
RBAC allows cluster administrators to easily manage authorization for users and applications accessing Kubernetes resources through roles and bindings. Common examples include:
- Granting developers write access to deployments in their namespace
- Binding a CI/CD tool’s service account to run validation tests
- Restricting administrator access only for cluster management tasks
By default, Kubernetes has some pre-defined roles like admin, edit, view etc. But custom roles can also be defined as needed to control fine-grained access.
Summary
In summary, Kubernetes RBAC provides a declarative approach to define and manage authorization for Kubernetes resources using roles and bindings. This allows securing clusters by granting only necessary permissions to different users and applications accessing the cluster.
Content input: Here are the key points about Kubernetes RBAC:
- Kubernetes RBAC (Role-Based Access Control) allows managing authorization to Kubernetes resources based on user roles and role bindings.
- Roles define a set of permissions (rules) that can be bound to users/groups to grant access to resources. There are two types of roles - ClusterRoles for cluster-wide access and Roles within a namespace.
- Roles/ClusterRoles specify the resources (API objects) and verbs (actions like get, create, delete) that can be performed on them.
- RoleBindings and ClusterRoleBindings are used to bind roles to users, groups, or service accounts to grant the permissions defined in the roles.
- RoleBindings bind roles to subjects within a namespace, while ClusterRoleBindings provide cluster-wide access by binding ClusterRoles.
- RBAC allows administrators to define custom resource access control policies based on user identities like dev/qa/prod teams.
- Some default roles like admin, edit, view are predefined, but custom roles can also be defined as needed for fine-grained access control.
- Together roles and bindings provide a declarative way to manage authorization for different users/services to access Kubernetes APIs and resources securely.
Content input: Here is a step-by-step guide on how to set up and use Kubernetes RBAC:
1. Create Roles
Roles define permissions - what actions can be performed on which resources. Create role manifest files: ```yaml kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: development name: pod-reader rules:
- apiGroups: [””]
resources: [“pods”]
verbs: [“get”, “watch”, “list”]
```
2. Create Role Bindings
Bind roles to users/groups using RoleBindings: ```yaml kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: read-pods namespace: development subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
## 3. Apply Manifests Apply the role and binding manifests:kubectl apply -f role.yaml -f rolebinding.yaml
## 4. Verify Access Jane can now run pod commands in the development namespace:kubectl –as=jane get pods -n development ```
5. Create ClusterRoles
Same process but for cluster-wide access.
6. Customize as Needed
Edit roles for new permissions or namespaces as authorization requirements change. Kubernetes RBAC enables securing access to Kubernetes APIs and resources through roles and bindings.
Content input: Here is some sample YAML for additional Kubernetes RBAC configuration:
ClusterRole
Grant cluster-wide access to get/list nodes: ```yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: node-viewer rules:
- apiGroups: [””]
resources: [“nodes”]
verbs: [“get”, “list”, “watch”]
```
##
 Commuting Options from Western Mississauga to Kitchener-Waterloo
Commuting Options from Western Mississauga to Kitchener-Waterloo