Managing Pods and Nodes
Kubernetes provides essential abstractions to deploy and manage containerized applications at scale. Two of the fundamental abstractions are Pods and Nodes. In this article, we’ll explore these concepts in-depth to help understand how Kubernetes schedules and runs applications.
Understanding Pods
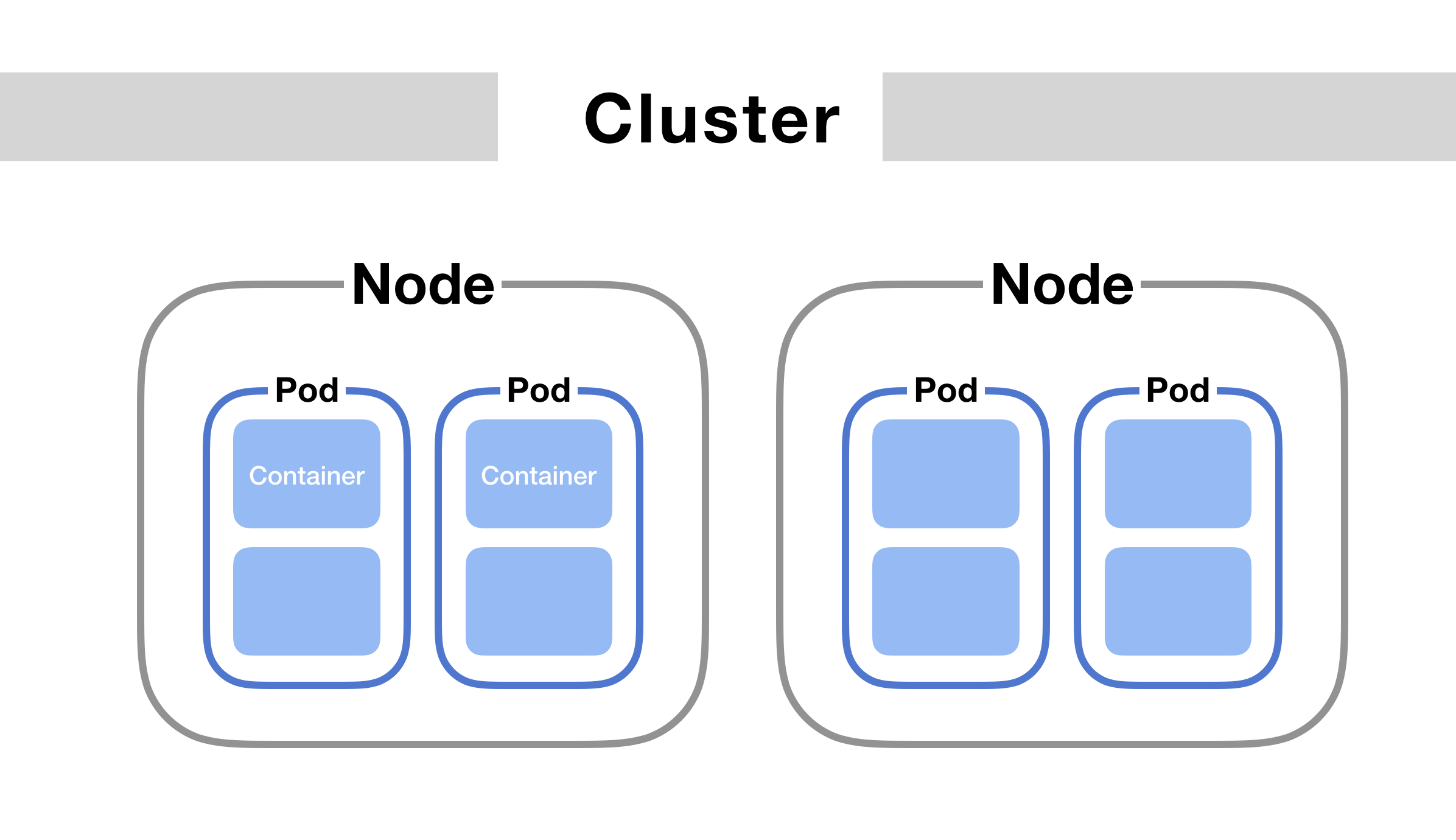
Pods are the basic execution unit in Kubernetes - they represent one or more containers running on your cluster and sharing storage and network resources. Every Pod is assigned a unique IP address within the cluster’s internal networking environment. Kubernetes automatically handles restarting Pods if they crash or are terminated. Some key things to know about Pods:
- Containers within a Pod always run together on the same Node in the cluster and share certain resources like volumes. This ensures tightly coupled containers remain together.
- Pods are not intended for durable storage since they can be rescheduled on different Nodes. For persistence, use
Volumesto share data between containers and across Pod reschedulings. - Labels allow categorizing and selecting Pods. Service discovery leverages labels to communicate between Pods running distributed applications.
- Pod disruption budgets help make Pods highly available by preventing evictions and limiting rescheduling during upgrades or repairs.
- Pod termination, readiness and liveness probes help control and monitor container lifecycles for auto-recovery and self-healing behaviors. Understanding the unit of deployment and execution helps when leveraging Kubernetes to optimize application design and deployment strategies.
Exploring Pod Configurations
Configuration defines how Pods run their containers and what resources they have access to. A simple Pod may only run a single container, but often there are multiple containers sharing resources through volumes and networks. Some common Pod configurations include:
Init containersfor pre-launch configuration like downloading dependencies before the primary app container starts.Sidecar containersoffer additional functionality like proxies, backup services or data collection alongside the main app.Ephemeral containerslaunch short-lived debugging containers alongside running pods without disrupting the main application containers.Volumesbind mount host paths or use storage volumes to persist and share data across containers in a Pod.Resourceslike CPU/memory requests and limits prevent bottlenecking one container from impacting others in the same Pod. Experimenting with Pod configurations helps understand how to run multi-container microservices and build robust, reusable application components on Kubernetes.Deploying to Nodes
Understanding Kubernetes Nodes
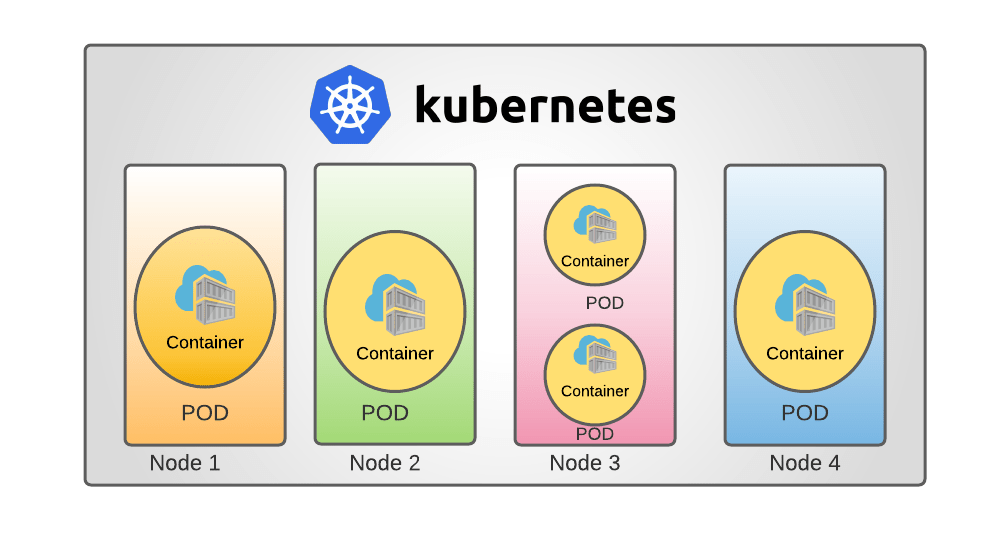
Nodes are the worker machines - VMs or physical servers - that run application containers and Pods in the Kubernetes cluster. The control plane automates distributing Pods across available Nodes to optimize workload distribution based on resource constraints and application requirements. Some key properties of Nodes:
- Each Node runs the Kubernetes control plane agent
kubeletto communicate with the master and run container workloads. - Nodes also run a container runtime like Docker or containerd to launch app images locally.
- Labels allow identifying Node properties like availability zones, hardware types or taints/tolerations to control scheduling.
- Probes monitor Node resources and connectivity to report status to the master for scheduled maintenance and repairs.
- Draining gracefully moves workloads off Nodes before maintenance shutdown or upgrade to minimize disruption.
Understanding Nodes helps optimize cluster topology and utilization as well as control scheduling and resource allocation strategies.
Scheduling Pods on Nodes
Kubernetes clusters start with a single Node that provisioned VMs or containers represent. As demand grows, operators add more Nodes for workers to schedule Pods across all available resources in the cluster. Some factors that influence Pod scheduling include:
- Resource requests, guarantees and constraints a Pod specifies for CPU, memory, GPU etc.
- Node labels, taints and tolerations that identify or restrict where Pods can land.
- Pod anti-affinity rules avoid co-locating pods that shouldn’t share infrastructure.
- Pod topologies place related pods near each other for performance or compliance.
- Resource availability and Node conditions aid optimized packing and spread of workloads.
Monitoring scheduled Pods and Node resource usage over time helps operators scale capacity, tune resources and improve deployment strategies to maximize cluster efficiency.
Exploring Cluster Operations
Managing Pods and Nodes
Administrators use
kubectlCLI to monitor and troubleshoot clusters by interacting with the Kubernetes API. Key operations include: - Pod operations like
get,describeprovide runtime status, container logs and lifecycle events. - Node operations allow
cordoning/uncordoning for draining, updating labels and viewing allocatable vs. used resources. - Troubleshooting with
top,logsandattachhelps debug pod startup failures or performance issues. - Scaling controllers up/down to add/remove nodes from the cluster’s capacity using Auto Scaling Groups.
Leveraging these views and interactions offers observability into the control plane’s scheduling decisions and how well workloads run on allocated infrastructure.
Maintaining High Availability
For production-grade deployments, operators must design for high availability and disaster recovery:
- Running multiple Kubernetes masters behind a load balancer provides a single API entrypoint.
- Deploying etcd as a replicated backing store ensures the control plane survives single points of failure.
- Distributing Nodes across availability zones automatically recovers pod failures due to zone outages.
- Using node pools with auto-scaling helps right-size capacity per workload requirements.
- Implementing taints and tolerations on Nodes reserves hardware exclusively for mission-critical services.
Proper cluster design starts with understanding how its components fit together to deliver continuous operations even during failures or planned maintenance.
Summary
In this in-depth guide, we explored two fundamental Kubernetes abstractions - Pods and Nodes. We learned how Pods bundle and manage containers, how Nodes run Pods, and how the control plane automates scheduling and operations across the cluster. Mastering these concepts provides a strong foundation for optimizing application deployments, monitoring infrastructure usage and maintaining resilient Kubernetes operations at scale.
 How a Few Extra Lines of Code Saved $5 Million
How a Few Extra Lines of Code Saved $5 Million